DOM获取
什么是DOM?
具体可以访问:HTML DOM 简介
看不懂也没关系,稍微了解一下即可。下面给出几个示例,也许你会更直观的明白。
假如一个网页的源代码如下所示
<div class="test">要取的内容</div>
如果你想取到div里面的内容,怎么写?
用DOM方式这样获取: div[class=test]。
这是最简单是示例了。再比如
<div id="test">要取的内容</div>
DOM写法:div[id=test]。 要是元素不是一个div,而是一个span,如下:
<span id="test">要取的内容</span>
也很简单,DOM写法:span[id=test]
稍微复杂一点的结构,如下
<div class="test"><span id="mytest">要取的内容</span></div>
DOM写法:div[class=test] span[id=mytest]
好了,四个例子,足以说明一切。现在你可以使用采集器获取绝大部分网页中你想要的内容了。如果你有耐心,请往下看
规则的简写
每次都输入div[class=test]或者span[id=test]这样的东西,太麻烦了。整理上面的几个例子,所以我们可以简写:
| 完整的写法 | 简写 |
|---|---|
| div[class=test] | div.test |
| div[id=test] | div#test |
| span[id=test] | span#test |
| div[class=test] span[id=mytest] | div#test span#mytest |
注意: div[class=aa bb] 像这样,一个class有两个值,这种情况下不能简写。
一些高级的写法
| 过滤 | 描述 |
|---|---|
| 属性 | 匹配具有指定属性的元素。如 div[id] 表示通过id属性 查找所有的 |
| !属性 | 匹配不具有指定属性的元素。 如 div[!id] 表示 查找所有没有id属性的 |
| [属性=value] | 匹配具有指定属性值的元素。如 div[id=test] 表示查找id=test的div元素 |
| [属性!=value] | 匹配不具有指定属性值的元素。 如 div[id!=test] 表示查找id不等于test的div元素 |
| [属性^=value] | 匹配包含特定前缀的值的指定属性的元素。如 div[id^=test] 表示查找id前缀为test的div元素 |
| [属性$=value] | 匹配包含特定后缀的值的指定属性的元素。如 div[id$=test] 表示查找id后缀为test的div元素 |
| [属性*=value] | 匹配具有指定属性的元素,且该属性包含了一定的值。如 div[id*=test] 表示查找id包含test的div素 |
使用DOM获取列表链接
凡是获取列表链接,都分成两行,比如要获取如下的列表
html内容:
<ul class="page_list">
<li><a href="detail.php?page=1">第1个链接</a></li>
<li><a href="detail.php?page=2">第2个链接</a></li>
<li><a href="detail.php?page=3">第3个链接</a></li>
<li><a href="detail.php?page=4">第4个链接</a></li>
<li><a href="detail.php?page=5">第5个链接</a></li>
<li><a href="detail.php?page=6">第6个链接</a></li>
<li><a href="detail.php?page=7">第7个链接</a></li>
<li><a href="detail.php?page=8">第8个链接</a></li>
<li><a href="detail.php?page=9">第9个链接</a></li>
<li><a href="detail.php?page=10">第10个链接</a></li>
</ul>
DOM写法:
ul.page_list li
a
具体的地址:http://www.dxcer.com/demo/page_list.php
放入采集器中,测试如图:
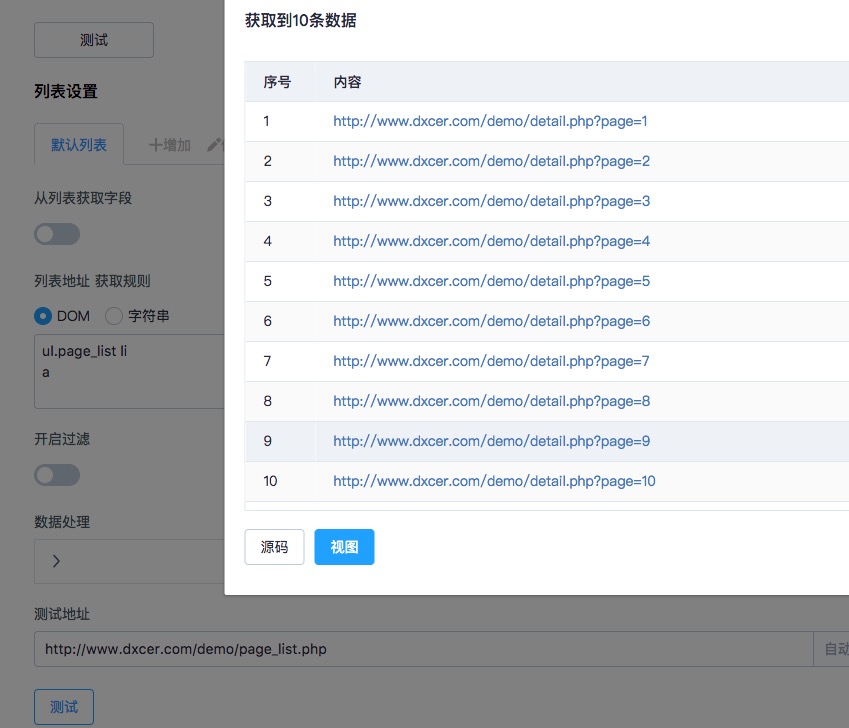
其中,规则分成两行。第一行是循环区域,第二行是取里面的a标签。如果下面只有一个a标签,一般写a就行了。如果下面有几个a标签,需要进行额外的指定,比如
ul.page_list li
a.test